Un aspecto importante para cualquier análisis de datos es acceder a
los datos!! Éstos pueden estar almacenados en diversos formatos:
archivos de texto (*.txt, *.dat, etc), texto
separado por comas (*.csv), planillas de cálculos
(*.xls o *.xlsx), etc.
Existen diversas funciones que vienen por defecto en
R o bien en paquetes específicos que permiten leer
virtualmente cualquier formato de archivos. El paquete rio
brinda una interfase unificada y simplificada para realizar esta tarea
desde la consola. Otra alternativa es el modulo
Import dataset de RStudio.
A continuación veremos como cargar el archivo urbana_weather.xlsx que contiene datos meteorológicos de la ciudad de Urbana (IL).
Desde la consola (recomendado)
Una vez que descargamos el archivo datos en la carpeta
data dentro de nuestro directorio de trabajo o proyecto
podemos leerlo en R usando la función
import() del paquete rio. Esta función se
encargará de llamar la función necesaria para leer el archivo que le
suministremos.
# Cargar rio (si no estaba cargado antes)
pacman::p_load(rio)
# importar los datos
urbana <- import("./data/urbana_weather.xlsx", setclass = "tibble")
urbana
# A tibble: 240 × 4
YEAR month precip temp
<dbl> <chr> <dbl> <dbl>
1 2000 Jan 1.54 25.6
2 2001 Jan 1.32 25.4
3 2002 Jan 2.81 34
4 2003 Jan 0.79 21.1
5 2004 Jan 2.18 24
6 2005 Jan 6.2 27.8
7 2006 Jan 1.78 37.8
8 2007 Jan 3.03 29.7
9 2008 Jan 2.31 26.2
10 2009 Jan 0.68 18.8
# … with 230 more rowsEl argumento setClass permite especificar en que tipo de
objeto importarlo. Por defecto es un data.frame. En este
caso mostramos como indicar que queremos crear un objeto tipo
tibble, que es un data.frame con
anabólicos.
Si sólo estuvieramos ineresados en el rango A1:C5
(primeros 4 registros de las 3 primeras columnas), podríamos usar:
urbana2 <- import(file = "./data/urbana_weather.xlsx", range = "A1:C5")
urbana2
YEAR month precip
1 2000 Jan 1.54
2 2001 Jan 1.32
3 2002 Jan 2.81
4 2003 Jan 0.79Desde el importador de datos de RStudio
RStudio cuenta con un asistente de importación de
datos (File > Import Dataset) que brinda interfase a
varias funciones especializadas en la importación de datos de paquetes
específicos como readr, readxl, etc.
En el menú File > Import Dataset o bien el ícono del
panel Environment despliega una lista con disitintas
opciones de importación: nos interesa
From Excel (readxl)...
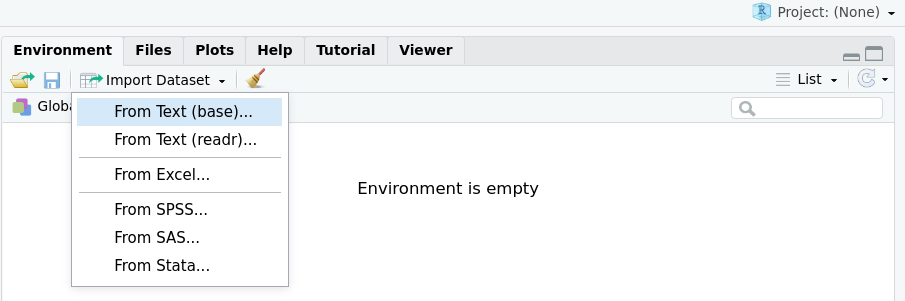
Figure 1: Importador de datos
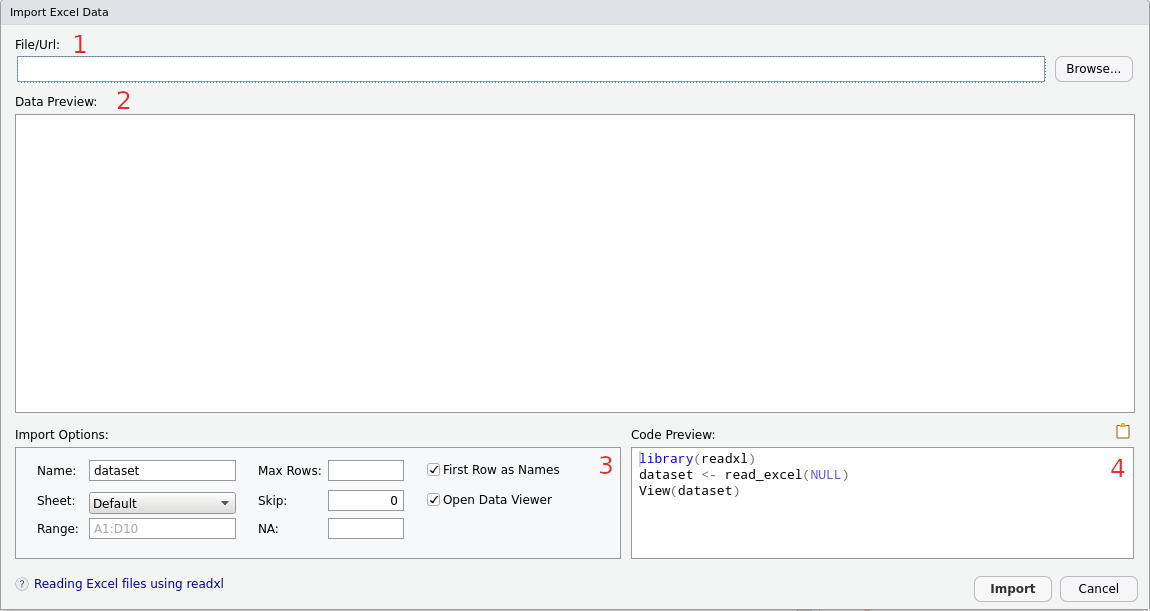
Figure 2: Importador de datos
Este menú tiene cuatro paneles:
Una barra de direccion para indicar la ruta al archivo o URL.
Una vista previa del contenido del archivo
Opciones de importación: aquí se puede especificar el nombre del objeto que se creará dentro de R (
Name), la cantidad de lineas a leer, el número de la hoja, el rango de celdas, líneas a saltear (skip) y el identificador de datosNA.Vista previa del código. En esta parte se puede visualizar como se construye el comando que se ejecturará al clickear en
Import.
Aclaración: es muy importante que el código generado por este asistente sea incluido en el script para futuras sesiones.
Verificación de los datos
Una vez importados los datos es conveniente verificar como han sido leidos en el R.
Como vimos antes, una alternativa es imprimirlo escribiendo el nombre del objeto directamente en la consola.
urbana
# A tibble: 240 × 4
YEAR month precip temp
<dbl> <chr> <dbl> <dbl>
1 2000 Jan 1.54 25.6
2 2001 Jan 1.32 25.4
3 2002 Jan 2.81 34
4 2003 Jan 0.79 21.1
5 2004 Jan 2.18 24
6 2005 Jan 6.2 27.8
7 2006 Jan 1.78 37.8
8 2007 Jan 3.03 29.7
9 2008 Jan 2.31 26.2
10 2009 Jan 0.68 18.8
# … with 230 more rowsOtra alternativa es utilizar la función View() que
muestra la tabla de datos en un formato de planilla interactiva de solo
lectura.
View(urbana)
Si bien podemos inferir que tipo de datos se leyeron, una alternativa
mejor es mirar la estructura con la función str().
str(urbana)
tibble [240 × 4] (S3: tbl_df/tbl/data.frame)
$ YEAR : num [1:240] 2000 2001 2002 2003 2004 ...
$ month : chr [1:240] "Jan" "Jan" "Jan" "Jan" ...
$ precip: num [1:240] 1.54 1.32 2.81 0.79 2.18 6.2 1.78 3.03 2.31 0.68 ...
$ temp : num [1:240] 25.6 25.4 34 21.1 24 27.8 37.8 29.7 26.2 18.8 ...Esto nos está diciendo que el objeto es un tibble donde
cada columna es una variable y cada fila una observacion. En nuestro set
de datos hay 4 variables (YEAR, month,
precip and temp) y 240 observaciones. Junto
con el nombre de cada variable hay una breve descripción del tipo de
datos (int para integer, chr para
character y num para numeric) y
una vista previa de los primeros valores.